Wide variety of applications in high performance computing faced issues with scalability of file systems like NFS (Network File Systems) which led to the adoption of distributed file systems based on object based storage architecture. Object storage improved the scalability by separating the file system meta operations and the data storage operations. The meta operations are handled by metadata servers (MDS) while the traditional block level interface was replaced by object storage devices (OSD). Clients interact with MDS to perform meta operations like open and then directly interact with OSD to store the data which in-turn delegates the data placement to devices themselves. Reliance and operations done by MDS and not having enough intelligence in OSD constrained the scalability and CEPH tried to mitigate it.
System Overview
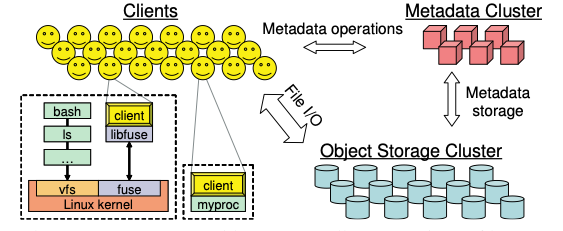
CEPH eliminates file allocation tables which involve metadata updates by using a distribution function called CRUSH. This reduction in dependency on MDS during file operations improves scalability. File data is striped onto predictably named objects and CRUSH assigns the objects to storage devices. This intelligence is used by the client and OSD reducing considerably the interaction with MDS.
CEPH MDS is also highly adaptive and distributed which dramatically improves the scalability of meta access and in-turn the scalability of the file system. CEPH MDS architecture is based on dynamic subtree partitioning that lets it to distribute metadata among tens of MDSs.
Given that any distributed system like CEPH will experience failures, growth etc which requires addition and removal of storage, CEPH delegates the responsibility for data migration, replication, failure detection and recovery to the cluster of OSDs. While OSDs provide a logical object store to clients and MDS, they can leverage the knowledge about the state of the system to achieve reliable, highly available object store with linear scaling.
Applications that need to use CEPH can directly link to a CEPH client or interact with CEPH as a mounted file system via FUSE. When a process opens a file, the client sends a request to the MDS cluster which traverses the file system hierarchy and translates the file name to a file inode which includes a unique inode number, the owner, size, mode etc. If the client has access to the file, the inode number, file size and the striping strategy used to map the file to objects is returned to the client. Armed with this data client can name and locate all the objects containing the file data using CRUSH and directly read from the OSD cluster. Similarly when a new file is open for writing, the client can write data directly to the OSD using CRUSH eliminating the need to interact with MDSs.
POSIX semantics requires that read reflects previous writes and that writes are atomic. When a file is accessed by multiple clients for reads and writes, MDS will revoke any caching and buffering capabilities issues previously forcing the I/O operations to be synchronous. Since synchronous operations are slower, CEPH offers POSIX extensions like O_LAZY flag for clients to perform I/O operations asynchronously.
Metadata read operations like readdir, stats and update operations like unlink, chmod are applied synchronously by MDS for security, consistency and safety without taking a lock. CEPH optimizes common metadata access scenarios like readdir followed by stats. In this case, CEPH will return the briefly cached data from readdir for the stats call. When multiple clients have opened a file for writes, a stats request against the file will involve revoking the write capability of all the clients, collect up-to date size and mtime value from all the clients, return the highest value for the stats request and reissue the write capabilities to all the clients. This is required to ensure proper serializability.
Metadata Management
While metadata requests are serviced by in-memory cache in MDS, meta is flushed to ODS for recovery. Metadata is distributed in an MDS cluster based on a dynamic partitioning strategy that adaptively distributes cached metadata hierarchically across a set of nodes. An authoritative MDS is responsible for managing cache coherence and serializing updates for a given piece of metadata. Each MDS in the MDS cluster measures the popularity of metadata within the directory hierarchy using counters with an exponential time decay. Any operation increments the counter on the affected inode and all of its ancestors up to the root directory, providing each MDS with a weighted tree describing the recent load distribution. MDS load values are compared and subtrees of the metadata hierarchy are migrated to keep the workload evenly distributed. During metadata migration, additional journal entries are written on both MDSs and in addition the imported meta data is written to the new MDS’s journal for failure recovery.
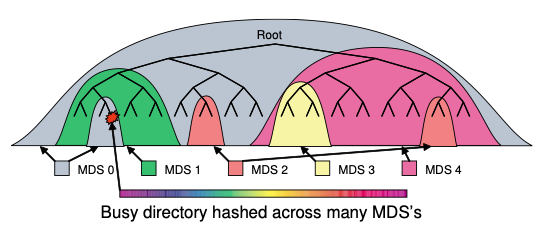
CEPH also uses the knowledge about the metadata used to distribute popular metadata to reduce hotspots. Contents of heavily read directories are selectively replicated across multiple nodes to reduce load. Directories that experience heavy write workloads have their contents hashed by file name across the cluster to achieve a balanced distribution of workload at the expense of directory locality. Clients are directed to authoritative MDS for updates while it is directed to random nodes for read operations.
Distributed Object Storage
CEPH clients and MDS view ODS clusters as a single logical object store and namespace. Ceph’s RADOS (Reliable Autonomic Distributed Object Store) achieves linear scaling in both capacity and aggregate performance by delegating management of object replication, cluster expansion, failure detection and recovery to OSDs in a distributed fashion. Ceph first maps objects to placement groups (PG). Placement groups are then assigned to OSDs using CRUSH (Controlled Replication Under Scalable Hashing) a pseudo-random data distribution function that efficiently maps each PG to an ordered list of OSDs upon which to store object replicas. CRUSH maps PGs onto OSDs based on placement rules which determines the level of replication and any constraints on placement like using OSDs on different racks.
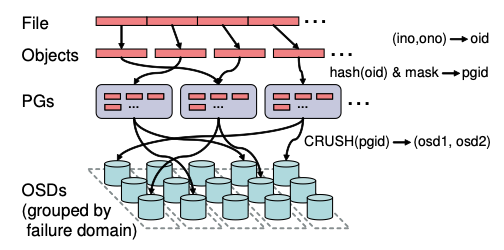
When a client sends write requests for an object, it is sent to the one of the OSD in the object’s PG which in-turn sends the write to additional replication OSDs. Once the replication OSDs had applied the changes they respond to the primary OSD which in-turn applies the writes and acknowledges the client. While this ack is generated when all the OSDs update the in-memory cache and a second ack is sent to the client when the changes are persisted to make sure that the changes can withstand failures. The client buffers the writes until the second ack is received to avoid data loss. Client read requests are sent to the primary OSD in the PG.
Instead of relying on the local filesystem like ext3, Ceph manages its local object datastore using EBOFS (Extent and B-Tree based Object File System). EBOFS is implemented entirely in user space and interacts directly with raw block devices.
Failure Detection and Recovery
OSDs in a PG monitor liveness of other OSDs. While replication acts as a passive confirmation of liveness, when an OSD is not heard from a peer recently, an explicit ping is sent. Non-responsive OSD is marked as down initially and if the OSD doesn’t recover quickly it is marked asout and another OSD joins PG to re-replicate its contents. Clients which have pending operations with the failed OSD will resubmit the request to the new primary. By marking OSDs as down, RADOS prevents initiating widespread data re-replication. Failures like disk failures or data corruption OSDs self report them.
To identify transient failures and system wide failures, a small cluster of monitors collects failure reports. Monitors provide an updated cluster map when failures are identified and they are distributed via the inter OSD communication. When an active OSD receives an updated cluster map, it iterates over all locally stored placement groups and calculates the CRUSH mapping to determine which ones it is responsible for, either as a primary or replica. If the OSD is the primary for the PG, it collects current (and former) replicas’ PG versions. If the primary lacks the most recent PG state, it retrieves the log of recent PG changes from current or prior OSDs in the PG in order to determine the correct (most recent) PG contents. The primary then sends each replica an incremental log update, such that all parties know what the PG contents should be, even if their locally stored object set may not match. Only after the primary determines the correct PG state and shares it with any replicas is I/O to objects in the PG permitted. OSDs are then independently responsible for retrieving missing or outdated objects from their peers. If an OSD receives a request for a stale or missing object, it delays processing and moves that object to the front of the recovery queue.