Bigtable is Google’s distributed key value data storage system which can scale thousands of machines storing petabytes of data.
- Provides a simple data model that supports dynamic control over data layouts and formats unlike relational data model
- Allows clients to reason about the locality properties of the data represented in the underlying storage
- Data in indexed by row and column names that can be arbitrary strings
- Data is treated as a uninterpreted strings but clients can serialize data in various forms into these strings
- Its schema lets clients to dynamically control whether the data need to be served out of disk or memory
Data Model
Data is stored as a multi-dimensional sorted map which is sparsely populated and distributed across multiple nodes. The map is indexed by row key, column name and timestamp and value in the map is an uninterpreted array of bytes.
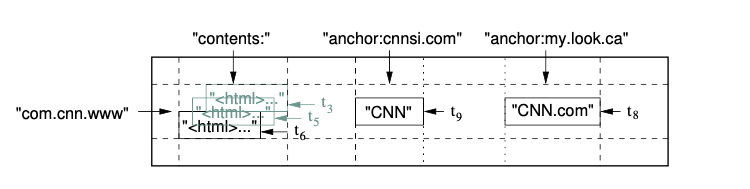
Row keys are arbitrary strings and every read/write operation is atomic regardless of the number of columns of the row involved in the operation. Rows are stored in lexicographical order by row keys are partitioned by row range dynamically. Each row range is called a tablet and is the unit of distribution and load balancing. Client operation on a range of rows will involve only a small set of machines where the tablets for the range is stored.
Column keys are grouped into sets called column families which forms the basic unit for access control and it need to be created before storing any column value. The column key is named using the syntax “family name:column name” and all the columns in a column family is compressed together when enabled. The number of columns in a table is unbounded but the number of columns in a column family can be in the hundreds.
Each cell which is qualified by “rowkey:column family:column name” can have multiple versions and these versions are indexed by timestamp which are 64 bit integers. The timestamps can be assigned by the client or Bigtable assigns the real time in microseconds and cells are stored in decreasing timestamp order so that most recent version is read first. Users can set the number of versions to be stored per column family and Bigtable will perform automatic garbage collections to prune the table to store only the required number of versions.
Bigtable also provides APIs for applications to read, write and scanning of data over a key range. Scans allows clients to limit data by selecting only a subset of column families, limiting the number of columns and also the timestamp. The APIs also support single row transactions which can be used to perform read-modify-write sequences on a single row and also supports cells to be used as integer counters. Similar to stored procedures in relational databases, Bigtable also allows client supplied scripts written in Sawzall to be executed in its address space to perform filtering, transformations and operations on data but does not allow writing back to the tables.
Internals
Google’s SSTable file format is used to store data on file and Bigtable leverages Google Filesystem (GFS) as its file storage which provides replication for availability and fault tolerance. Each SSTable contains a sequence of blocks which is 64 KB by default and a block index is stored at the end of SSTable which is used to locate blocks. The block index is loaded into memory when a SSTable is opened. For a read request once the block is identified from the block index then a single disk seek is used to retrieve the data from the block. Optionally the complete SSTable can be configured to be completely mapped into memory which will make the data to be served completely from memory. Each tablet comprises of multiple SSTable files
Bigtable consists of a master server which assigns tablets to multiple tablet servers. Apart from assigning tablets to tablet servers, master is also responsible for expiration of tablet servers, load balancing tablet servers, garbage collection of files in GFS and managing table metadata. Each tablet server manages a set of tablets, handles read/write requests to tablets and splits tablets when they grow large.
Chubby which is a distributed lock service in Google is used to make sure that there is only one active master at any time. It is also used to discover tablet servers and finalize tablet server deaths. Table schema information is also stored in Chubby along with the access control lists.
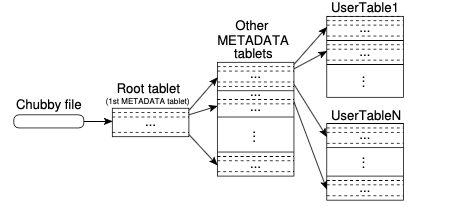
Chubby stores the location of root tablet which contains location of all tablets in a special METADATA table. Each METADATA tablet contains the location of a set of user tablets and the root tablet is just the first tablet in the METADATA table, but is never split. The METADATA table stores the location of a tablet under a row key that is an encoding of the tablet’s table identifier and its end row. Clients cache the tablet locations and it gets refreshed when data gets stale.
When a tablet server starts it acquires a lock in Chubby and the master requests for the lock status periodically. A lock gets released when a tablet server is not able to reach Chubby due to a network partition or machine failure. Master is informed about the loss of the lock and it tries to reach Chubby to make sure that the service is alive. If it finds the Chubby service to be alive it takes out the tablet servers from its list of tablet servers that serves data and distributes tablets stored in the failed tablet server to other tablet servers. If in case the tablet server connectivity to Chubby service is restored and tries to acquire the previously held lock, it will fail and it will shutdown itself to restart and create a new lock.
Master also takes an exclusive lock in Chubby when it starts and if the session with Chubby fails, master will kill itself. The exclusive lock makes sure that there is only one Master alive at a time. When a new master service comes up, it scans Chubby to find all the live tablet servers and communicates with them to discover all the tablets stored in them. It also scans the METADATA table to identify any tablets which is not assigned to assign them.
During a write request, the client identifies the tablet and the tablet server to which the data need to be stored and send the request to the tablet server. The tablet server writes to a tablet log for recovery and also to an in-memory sorted buffer called memtable. When the buffer fills up it is flushed to disk and stored as SSTables. On read requests, the data for the SSTables and any latest data the in-memory buffer is merged to respond to the request. In order to minimize the number of SSTable files, a subset of these files are periodically merged to combine them into a single SSTable and the process is called merging compaction. A major compaction is run to merge all the SSTables into a single SSTable and during this process any deleted rows is also removed from the files. A delete request is marked by an additional row identifying the deletion and the deleted rows are not physically removed until major compaction.
Clients can group multiple columns families together into a locality group which will result in a separate SSTable generated for each locality group in each tablet. By grouping commonly accessed column families will result in better read efficiency. Clients can also enable compression for a locality group and the type of compression to be used which will be applied to each block in a SSTable.
To improve read performance, tablet servers uses two levels of caching. The block cache is the lower level cache used to cache data read from GFS and the scan cache is the higher level cache which stores the key-value pairs returned by the SSTable interface to the tablet server code. Block cache improves performance of queries that tend to read data which is close to the data which was recently read while scan cache helps queries that tend to read the same data repeatedly. Bloomfilters which can identity all SSTables in which the requested data is not available is used to help reduce the number of SSTables that need to be read that in-turn improves the read performance.