Globally distributed database that automatically shards data across many sets of Paxos state machines in datacenters spread all over the world. Replication is used for global availability and geographic locality; clients automatically failover between replicas. It automatically migrates data between machines to balance load and during failures.
- Compared to Bigtable, Spanner provides cross datacenter replicated data
- Provides strong consistency in the presence of wide area replication
- Applications can specify replication constraints
- Which datacenter can have which data
- How far data is from its users to control read latency
- How far replicas are from each other to control write latency
- How many replicas are maintained to control durability, availability and read performance
- Database features on top of distributes systems infrastructure
- Data is stored in schematized semirelational tables
- Data is versioned, and each version is automatically timestamped with its commit time
- Old versions of data are subject to configurable garbage-collection policies
- Applications can read data at old timestamps.
- Provides an SQL-based query language.
- Supports general-purpose transactions
- Made possible by the fact that Spanner assigns globally meaningful commit timestamps using TrueTime API
- TrueTime API exposes clock uncertainty and Spanner will slowdown when the uncertainty is large
Implementation
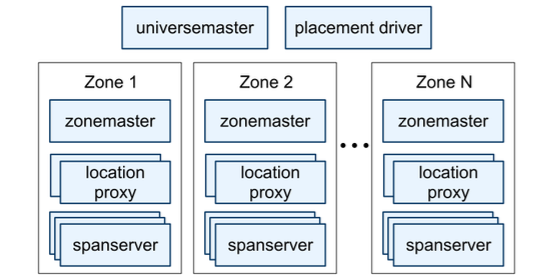
Spanner deployment is called the universe
- Organized as a set of Zones which are administrative units and set of locations for replication
- Zone has one Zone Master and between one hundred and several thousand span servers
- Zone Master assigns data to Span servers
- Span servers serve data to clients
- Zones can be added or removed from a running system
- Location proxies are used by clients to locate span servers which can serve the data
- Universe master is a console which provides status information of all zones
- Placement driver identifies data that need to be moved by communicating with span servers
- Zone has one Zone Master and between one hundred and several thousand span servers
Spanserver
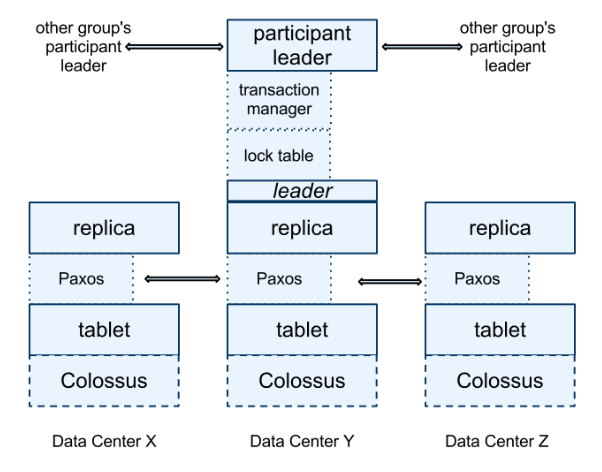
- Manages between 100 and 1000 instances of “tablets” which stores timestamped key value pairs
- Tablets state is stored in a set of B-tree like files and a WAL on a distributed filesystem (Colossus)
- For replication a Paxos state machine is created for each tablet and the set of replica is called Paxos group
- Leader in a Paxos group implements a lock table which maps range of keys to locks for concurrency control
- all transactional reads need two acquire locks while the others can bypass the lock table
- Leader in a Paxos group also implements a transaction manager to support distributed transactions
- Transaction manager coordinate a two phase commit when a transaction involved more than one Pax’s group
- With in each tablet Spanner implements an abstraction called directory which is a contiguous set of keys with common prefix
- Directories are units of data placement and applications can control the locality of data by choosing keys
- Directories makes moving data to reduce load from a Paxos group or to keep frequently accessed or data accessed together efficient
- Tablet is a container which can store multiple directories which in turn multiple key ranges for the same table or multiple tables
- Directory is the smallest unit for replication and when the size of a directory grows Spanner shards into multiple fragments. Fragments from a directory are the real unit of replication and fragments from a directory can be managed by multiple Paxos group
Data Model
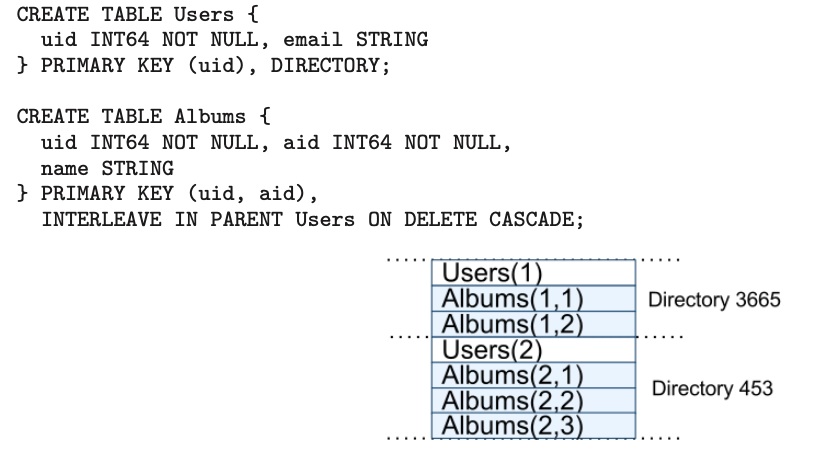
- support schematized semi-relational tables and synchronous replication
- Cross row transactions with the assumption that application programmers will take into account performance overhead
- Data model is layered on top of directory bucketed key value mappings
- Create database in a universe which can contain unlimited number of schematized tables
- Every row in a table need to have a set of one or more primary key columns
- Application can create a hierarchy of tables using “INTERLEAVE IN” clause which will lead to the storage of related rows in the same directory. This improves performance.
Truetime

- TT.now() will return TT.interval which will be within the error boundary and guaranteed to include the absolute time when now() is invoked
- TrueTime API is used by Spanner for concurrency control and is provided by Google infrastructure which used atomic clocks and GPS to implement
Concurrency Control
Spanner supports following transactions
- Lock free snapshot transaction: Should be pre-declared as not having any writes
- Non blocking reads/ snapshot reads for client chosen timestamp or bound
- Externally consistent transaction (Read write)
- Read with in read write transaction use wound-wait to avoid deadlocks
- Client issues read to the leader replica which acquires locks and reads the recent data
- Client sends keepalive messages to prevent participant leaders from timing out
- After reading and buffering all the writes, client initiates two phase commit first by choosing a coordinator Paxos group and sending each participant’s leader with the identity of coordinator along with any buffered writes
- All non coordinator participant leaders acquires a write lock, chooses a prepare timestamp greater than all any timestamp they have assigned to previous transaction and notifies the coordinator
- The coordinator leader also first acquires write locks, but skips the prepare phase.
- The coordinator chooses a commit timestamp for the entire transaction which is greater than all prepare timestamps received from participants, greater than all the timestamps the coordinator assigned to previous transactions and greater than TT.now().latest when the coordinator received its commit message
- The coordinator waits for unit TT.after(s), s being the commit time chosen before sending the commit time to client and all the participant leaders. Participants commits data with the commit time and release the lock
- Schema change transaction
- Similar to read write transaction but not blocking
- Uses future timestamp and hence all writes with timestamp greater that the transaction timestamp need to wait to commit