Requirements Dynamo tries to satisfy
- Data read and written are identified uniquely by a key
- Data size is small and stored as raw bytes that doesn’t require a relational schema
- Queries doesn’t span multiple data items i.e. user queries deal with only one row at a time
- Use cases that can tolerate weaker consistency for high availability and require no isolation guarantees
- Can be deployed on commodity hardware in a trusted environment that doesn’t require authentication or authorization
- Users will be able to control durability and consistency to make tradeoff between functionality, performance and cost effectiveness. This is in contrast to traditional database where consistency is favored over availability.
Dynamo design considerations
- Systems are prone to server and network failures
- Availability can be increased by using optimistic replication but need to be able to do conflict resolution and when I.e. whether during reads or writes
- Should be an always available datastore
- Incremental scalability to handle increase in user needs
- Symmetry of node responsibility i.e. no node is special
- Decentralization is favored over centralized control
- Heterogeneity of the environment should be expoited
Dynamo uses a synthesis of well known techniques to realize its features
- Partitioning using consistent hashing (Distributed Hash Table) and replication for scalability and availability
- Quorum based and decentralized replica synchronization protocol
- Merkle trees used to identify divergence in data stored in different replicas and recovery
- Eventual consistency to make it always write available
- Hinted handoff i.e. storing writes temporarily when nodes recover from temporary failures
- Object versioning for conflict resolution which can be dealt with at the storage or client layer. In Dynamo conflict resolution is done during reads using vector clocks
- Gossip based distributed failure detection and membership protocol which eliminates manual intervention to add or remove nodes
- Simple key/value user interface to interact with data using the key
Partitioning Algorithm
Dynamo uses consistent hashing where the output range of a hash function is treated as a fixed circular space or ring. Each node in Dynamo is assigned a random value within this space which represents its position in the ring. Each data item identified by its key is assigned to a node by hashing the key to identify its position in the ring and assigning to the first node in the ring with a position larger than the item’s position. This node is the coordinator node for the key for writes. Also by assigning items to nodes, adding or removing nodes to Dynamo impacts immediate neighbors and other nodes remain unaffected. To reduce non uniform distribution of data and load distribution due to random position assignment of nodes in the has ring , Dynamo uses virtual nodes. Each virtual node is assigned a position in the hash ring and each physical node is assigned multiple virtual nodes. Varying the number of virtual nodes based on physical node capacity, heterogeneity of the environment can be taken into account. If a node becomes unavailable, virtual nodes help in equal dispersement of load across other nodes.
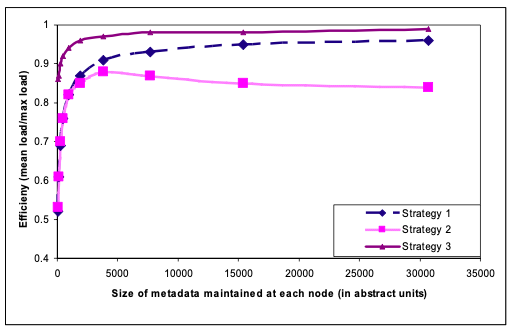
The following three partition schemes used and efficiency of load distribution compared
- Strategy 1: T random tokens per node and partition by token value
- Strategy 2: T random tokens per node and equal sized partition
- Strategy 3: Q/S tokens per node and equal sized partition where Q is the number of equally sized partition and S the number of nodes
Replication
The node to which a data item is assigned to is called the coordinator node which not only stores the data locally and also coordinates the replication of data to “N-1” number of nodes where N is configurable. Successive N-1 nodes in the ring after the coordinator node is selected for replication and are called preference list. Since multiple virtual nodes can be assigned to a single physical node, to avoid copies of replicated data is not stores in the same physical node, nodes are skipped to come-up with the preference list. If any of the nodes in the preference list is not available, another node will be selected to store the replica of the data with the meta data to hint to which the data belongs. When the target node becomes available, the data is delivered to the preferred node. Nodes storing the hinted handoff data can fail before it is replicated to the target node and it will end up replicas being not consistent. To prevent inconsistencies and to be able to recover quickly, Merkle trees on the data stored in each node is maintained and compared regularly. When a difference is found data is replicated in the background to bring back the replications to be insync.
Data Versioning
Dynamo uses vector clocks which is a list of (node, counter) pair in order to capture the causality between versions of same object. When multiple versions of data are retrieved during a read operation, if the counter and nodes in the versions are in order i.e. the nodes and counter of the last version contains all the nodes and the largest counter, then all the older versions can be forgotten. But if there are versions where is there is no causal dependency i.e. node in the (node, counter) pair is not the same in two versions then it need to be reconciled. The reconciliation can be done at the client using business logic, at the storage level with last write wins using physical timestamp or by setting the read replica to 1 and write replica to N which will make sure that all the replicas have the same version.