GFS is Google’s distributed filesystem to support their processing needs based on the following observations
Observations
- Component failures are the norm rather than the exception. Therefore monitoring, error detection, fault tolerance and recovery should be integral to the system
- Files are large by traditional standards and grows faster.
- Files are mutated by append operation rather than overwriting existing data
- Co-designing the applications and the file system APIs increases flexibility. For e.g. relaxing consistency model of filesystem reduces burden on the applications
Design Considerations
- The system should run on inexpensive commodity hardware that often fails
- The system should manage large files efficiently while it doesn’t have to be optimized for small files
- The primary workloads to be considered are large streaming reads and small random reads. Also large sequential writes which appends data and small number of writes to random positions which doesn’t have to be efficient
- Atomicity with minimal synchronization overhead is essential when multiple clients concurrently appends to the same file
- Should support data processing done in bulk at a high rate and hence high sustained bandwidth is more important than latency
Architecture
Files in GFS are divided into fixed size chunks of 64MB and stored in chunkservers which are commodity Linux machines running a user-level server process. The metadata about files like the chunks which form part of a file, the byte range, its namespace and the chunkservers where they are stored are all managed by a single master node. Filesystem metadata is stored in memory of the master and updates due to file creation or deletion is logged to operation log for failure recovery. The operation log is replicated to remote machines for recovery from master machine failure.
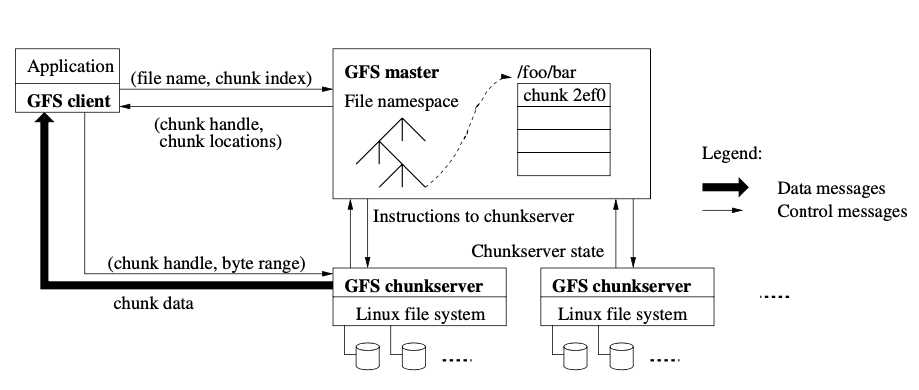
Each chunk is identified by an immutable 64 bit chunk handle and the master determines the check servers that will store a chunk when it is created and stores in the in-memory metadata. When a client requires to read data in a file, the GFS client converts the file name and the byte location to a chunk index and requests the master for the location. Master then sends back the chunkservers where the chunks are stored which then is used by the client. Not involving the master in the data read-write path makes GFS highly scalable. Chunks are replicated to multiple chunkservers (3 by default) for resiliency against chunkserver failures. One copy of all chunks is stored in a chunkserver which is not in the same rack as the previous two so that data is available for clients when there is a rack failure.
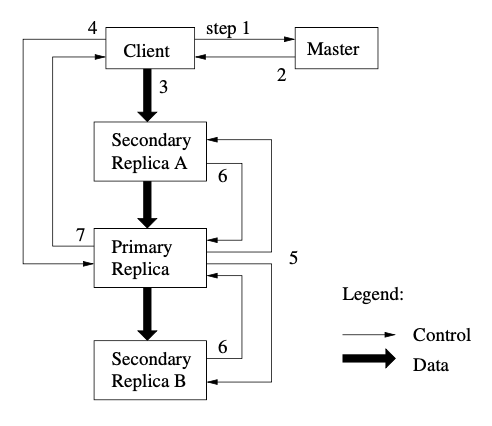
For writes, client receives from master the chunkservers to which the data need to be written and identifies one as the primary. The client then sends the data to be written to one of the chunkservers which then pipelines the data to other chunkservers to which the data need to be replicated to. After the data is send to all the chunkservers which then acknowledges after writing into its LRU cache, the client client sends a write request to the chunkserver as the primary along with the identify of data pushed. The primary assigns consecutive serial number to all mutations it receives and applies them locally in the serial order and also forwards to other replicas holding the chunk. Once all the replica cunkservers applies the mutations locally and informs the primary, the primary chunkserver acknowledges the client. The communication between chunksevers are over TCP. If a write crosses chunk boundary, the write is split and multiple write operations are initiated across multiple chunks.
Health of master is monitored using an external system and when there is a failure, a new master is brought up which inturn uses the operating log to build the metadata in-memory datastructue. In order to reduce the recovery time, regular checkpoints are taken when a master is alive which copies the in-memory data on a regular interval which can be mapped directly into the memory of a new master when it is brought up. Once the I’m-memory data is recreated, the new master will need to walk through the mutations which happened after the checkpoint that is logged in the operating log. When checkpoints are made the file chunks to chunkserver mapping is not saved. Instead the new master requests each chunkserver to send the chunks they store which is always kept current.
The health of chunkserver is known by the master through regular heartbeat messages send by the chunkservers and also GFS client informing the master if one of the chunkservers provided by master is not reachable. When a chunkserver is identified as unhealthy, the master identifies other chunkservers to which chunks need to be replicated and initiates the replication. The heartbeat message also includes chunks stored in a chunkserver and if the master identifies that a chunk is no more required like chunks created but not part of a successful write, it will initiate the garbage collection process to reduce the space use. The same process is used when files are deleted. In order to be able to recover a file deleted by mistake, GFS renames the deleted file and hence the chunks are kept in the system for a period of time during which the file can be recovered by renaming the file. After the time period, master deletes the metadata of the file and when a chunkserver informs about the chunk that belonged to the deleted file, the master sees that as garbage and informs the chunkserver to remove the chunk. Stale chunks are also identified when a chunkserver comes back online after a failure and sends heatbeat message to master and is subsequently removed.
Snapshot of a file or directory can be made quickly by GFS master making a copy of the metadata to create the snapshot file or directory which inturn points to the source chunks. Further mutations to the source, will create new chunks on the same chunkserver where original chunks were stored and data gets copied before mutation takes place i.e. copy on write. Given the visibility master has about the state of chunkserver like the amount of chunks it stores, its capacity, its load etc, the master can determine where new chunks should be stored so that the load is balanced. Also in the background it can initiate moving of replicas for rebalancing and recoverability.
Inorder to maintain data integrity and detect data corruption, chunks are broken into 64 KB blocks and checksum of each block is calculated and stored persistently separate from the data. This can be used by the client during reads and also in the background by chunkserver on unread chunks to check the data integrity.