Distributed internet scale hash table is a CAN and the concepts detailed in this paper can help in building a completely decentralized distributed system like a distributed datastore. The CAN described consists of multiple nodes and each node stores a chunk called the Zone of the entire hash table. In addition each node holds information about a small number of adjacent zones in the table. Requests for a particular key are routed by intermediate CAN nodes to the node which contains the key. The CAN described is completely scalable, fault tolerant, scalable and is implemented at the application level
Design
A d-dimensional Cartesian coordinate space on a d-torus which is completely logical and bears no resemblance to any physical coordinate system forms the basis of the design. The coordinate space is dynamically partitioned among among all the nodes in the system. The virtual coordinate space is used to store store the key value pairs of the hash table by mapping the keys to a point in the coordinate space using a deterministic hash function. The key value pair is then stored in the node that owns the zone that includes the point for the key.
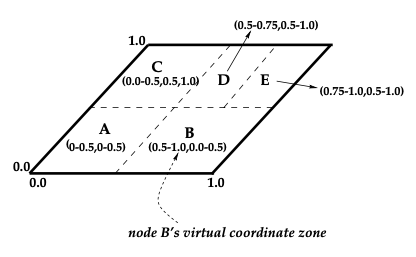
To retrieve data any node can use the deterministic hash function can find the point in the coordinate space. If the point is not in the zone owned by the node or its neighbors, the request will be routed to the target node through the CAN infrastructure. Nodes in the CAN self organize into an overlay network that represents the virtual coordinate space. Each node learns about the nodes which owns neighboring zones and stores them. This set of immediate neighbors serves as coordinate routing table that enables routing between arbitrary points in the coordinate points.
Routing
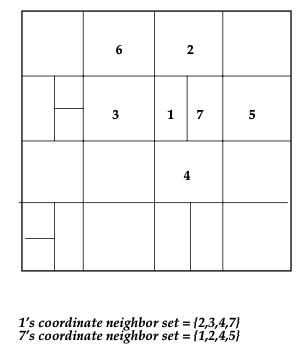
A CAN node maintains a coordinate routing table that holds the IP address and the virtual coordinate zone for each of its neighbors in the coordinate space. In a d-dimensional coordinate space, two nodes are neighbors if their coordinate spans overlap along (d - 1) dimensions and abuts along one dimension.
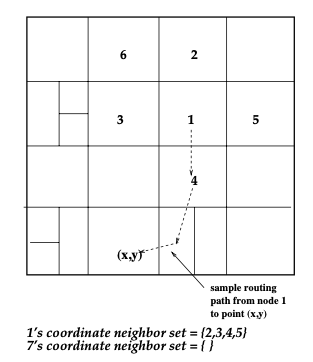
This local neighbor state is sufficient to route between two arbitrary points in the space. A node routes a CAN message which has the destination coordinates towards the destination by simple greedy forwarding to the neighbor with coordinates closest to the destination coordinates. If a node losses all its neighbors then greedy forwarding will fail. In this case, a node may use an expanding ring search (using stateless, controlled flooding over the unicast CAN overlay network) to locate a node closer to the destination from which greedy forwarding is resumed.
CAN Construction
CAN organically grows with addition of new nodes and when a node addition happens a portion of the coordinate space gets allocated to it. This Is done by splitting the zone in half from one of the existing nodes. When a node is added
- It is provided with the details about a partial set of nodes currently in CAN
- The new node chooses a random point P in the coordinate space and sends a request through the existing nodes which forwards them until the request reaches the node which owns the zone including the point. The current node spilts the zone and assigns half of it to the new node. While splitting a certain order in dimensions is assumed so that a split can be remerged when nodes leave
- The new node then learns about its neighboring nodes like the IP address and their zone details and at the same time the original node will update its neighbor set to remove nodes which are not its neighbors anymore. The neighboring nodes of the original node and also the new node will be informed about the change which then will trigger updates on these nodes. When a new node is added only and few nodes in the CAN has to go go through this update process which is O(d).
When a node need to depart gracefully, the zone of the departing node will be merged to a neighboring node and merging is not possible a neighboring node with smallest zone will handle to zone from the departing node temporarily. In the event of a node failure which is identified by neighbors by prolonged absence of message from a node, a takeover process id followed. Each neighboring node when it identifies a failed neighbor, a timer is initiated in them in proportion to the volume the zone in each node. When the timer expires, the nodes will send out a TAKEOVER message to all the neighbors of the filed node and all the neighbors receiving the message will cancel its own timer. This will make sure that the neighbor with the smallest volume will take over the zone from the failed node. In situations where only a half of the neighboring nodes are reachable, the node performs a wider ring search for nodes residing beyond the failure region to identify neighbor state to initiate the takeover process. Since the take over can result in nodes handling sub optimal number of zones, a background process will reassign zones so that CAN operates efficiently.
Design Improvements
Nodes adjacent in a CAN can be physically far away resulting in increased latency. The following are the improvements to reduce the latency between hops and also the number of hops to reduce the latency of CAN routing which is key. While the performance and the robustness improves the tradeoff is in increased per-node state and complexity.
- Increasing the dimensions of the CAN coordinate space reduces the routing path length and hence the path latency for a small increase in the coordinating routing table. With increase in the number of dimensions, number of neighbors for each node also increases that improves the routing fault tolerance.
- Additional coordinate name spaces called realities can be used and each node will support additional zones from each of the name spaces. This replication improves availability along with improving the routing since nodes can use the best reality to route.
- Using RTT metrics to each of the neighbors of a node to determine the neighbor to which to route CAN messages which will result in reducing latency.
- Sharing a zone among multiple nodes which results in each node storing its peers along with it peer. This results in reduced path length (number of hops) and also reduced hop latency since now the node has multiple choices in selecting neighbors and can select neighbors which are closer. This also increases fault tolerance since a zone is vacant only when all the nodes in a zone crashes simultaneously.
- By using multiple hash functions which maps a key to multiple nodes the data availability can be improved. Also queries for a key can be send to all the nodes storing the copies of the data in parallel which intern can reduce the latency.
- When a new node is added, instead of splitting the zone in a node to share with the new node, the volume of the zones in neighboring nodes are checked and the zone with the highest volume is split. This helps in load balancing.
- Caching and replicating most sought out keys in node improves query performance