Spikes in tail latency is a common challenge faced especially in large scale, parallel and interactive applications and this paper looks at the sources of this spike at the hardware, os and application layers. The study is done by performing tests and collecting fine grained measurements on three servers a custom null RPC service, Memchached and Ngnix on Linux. The measurements are compared against best achievable latency distribution by modeling these services as a queueing system. This comparison identifies the major sources of tail latency beyond that caused by workload bursts namely
- Interference from other processes including background processes on a seemingly dedicated machine
- Request re-ordering caused by scheduling policies that are not designed with tail latency in mind
- Application design choices involving how transport connections are bound to processes or threads
- Multi core issues such as how NIC interrupts and server processes are mapped to cores
- CPU power saving mechanisms
and quantify them.
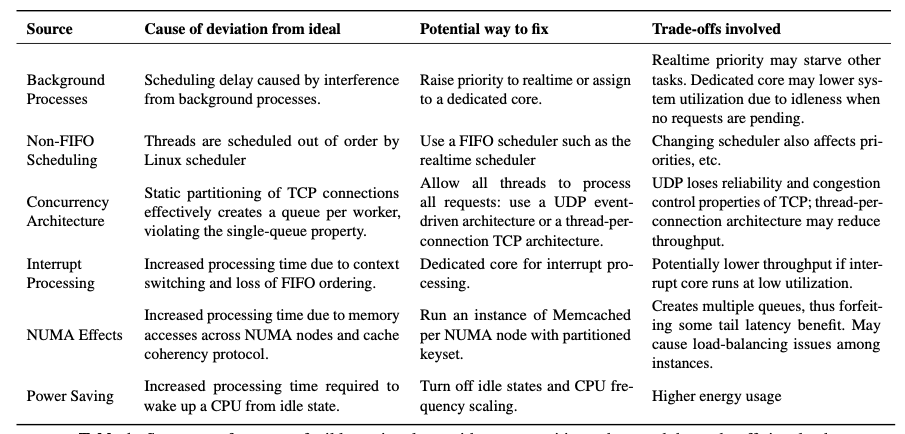
Summary of the findings
The following table provides the summary of findings on the cause of the spike in tail latency due to various factors and how they can be mitigated